
在上一篇文章中,我们讨论了数据块,我们讨论了两种不同类型的数据块,全局数据块和功能块FB的数据实例。
在本文中,我们将讨论西门子 Tia Portal 中优化数据块访问和标准数据块访问的含义。
内容:
- 什么是优化数据块和标准数据块?
- 简单的程序示例。
- 什么是标准 DB? 偏移量是多少?
- 什么是优化的数据库?
- 使用优化数据库的优点。
- 结论。
什么是优化和标准数据块访问?
首先,这些不是新类型的数据块;我们说过我们只有两种不同的类型:全局数据库和背景数据库。优化数据块访问是数据块的一项功能。您可以从已创建的数据块的属性中激活或禁用此功能。
优化数据块功能仅适用于 S7-1200 和 S7-1500 PLC,不适用于 s7-300 或 s7-400
使用 S7-1200 或 S7-1500 PLC 时数据块的标准设置是它们是经过优化的,如果您想要标准数据块,则必须自行设置。
那么,什么是优化块和标准块? 为了理解其中的差异,我们将编写一个简单的程序并尝试展示优化块与标准块的不同之处。
简单程序示例:
在此示例中,我们不会创建任何 PLC 逻辑或编写任何指令,我们只会创建 2 个全局数据块,DB1 将称为 OptimizedDB,DB2 将称为 StandardDB。
在这两个数据块中,我们将分别声明数据类型 Bool、Int、Real 和 Word 的 4 个变量。见图1。

图 1 – 创建两个全局 DB
首先你会注意到,两个数据块是完全相同的,那是因为正如我们所说,创建数据块时的默认设置是它会被优化,所以我们需要更改 DB2 的设置,使其成为 标准块,看看是否会发生变化。
我们根据 DB2 的属性来做到这一点。您可以通过右键单击数据块并按属性来访问 DB2 的属性。见图2。

图 2 – 将 DB2 更改为标准块访问
取消选择图 2 中所示的优化块访问属性并按 “确定” 后,将弹出警告消息,见图 3。

图 3 – 更改块访问弹出窗口
一旦按下 OK,您的 DB2 将被转换为标准块访问。请参见图 4。看看这有何不同。

图 4 – DB2 现在是一个标准块
我们直接看到的是 DB1 和 DB2 不再一样了。DB2 中表示的标准块访问选项有一个称为偏移量的附加列。
在偏移框中的每个变量前面,都有一个...写着,一旦你编译程序,这个就会改变。
让我们编译一下,看看会发生什么,见图 5。

图 5 – 编译程序以重新加载偏移量
现在,偏移量已分别填充为 0.0、2.0、4.0 和 8.0。
那么,这个偏移量是多少? 这是什么意思? 我们稍后会讨论这个问题,但现在,让我们创建另一个 STANDARD 块并声明相同的 4 个变量,但这次我们将更改变量数据类型的顺序,见图 6。

图 6 – 创建另一个标准块 DB3
从上图可以看出,DB2 和 DB3 的偏移量是不同的,为什么当我们改变数据类型的顺序时,偏移值会不同呢?它们是相同的数据类型,但顺序不同。
让我们创建另一个标准DB,并声明相同的 4 个变量,但顺序不同。编译您的 PLC 代码,然后比较 3 个 DB 的偏移量。见图7。

图 7 – 具有三个不同偏移量的三个不同 DB
同样的事情又发生了。
什么是标准 DB?偏移量是多少?
标准访问的数据块具有固定的结构。当您在标准 DB 中声明变量时,该变量将被分配到该 DB 中的固定地址。
该变量的地址显示在 “Offset” 列中。因此,我们在前面的图片中看到的偏移量是为每个变量分配的地址。
因为标准 DB 的结构是固定的,所以只能在具有固定存储容量的 DB 中工作,即 16 位区域或 2 字节。这就是当我们改变声明顺序时,相同变量的寻址不同的原因。更多解释请参见图 8。
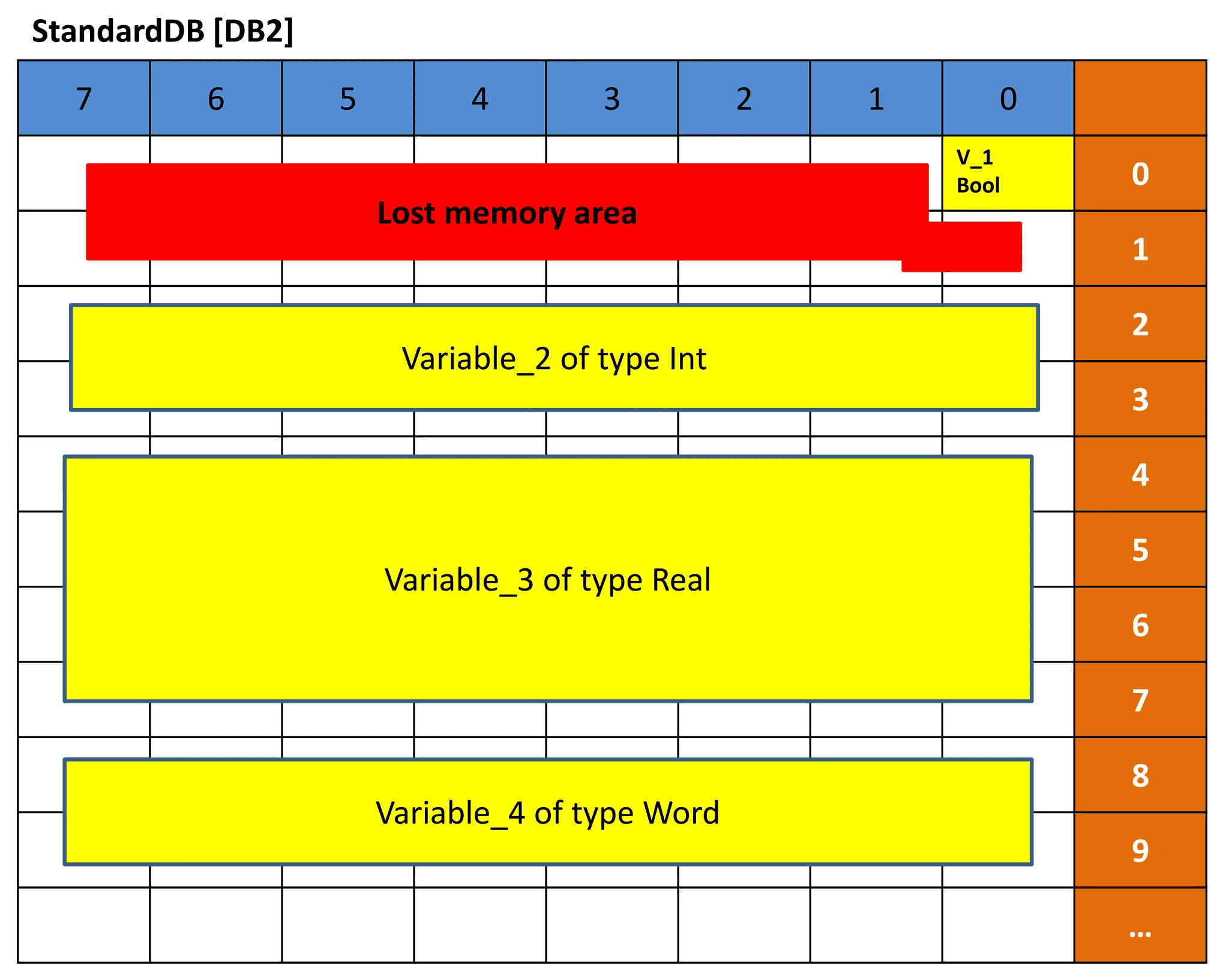
图 8 – DB2 的简单表示
图 8 显示了标准数据块 DB2 的简单表示。正如我们之前所说,标准DB具有固定的 16 位内存块,因此,当我们将 Variable_1 声明为 BOOL 数据类型时,该变量将占用全部 16 位,即使它只需要 1 位内存。这就是为什么您会看到其余区域标记为红色,因为它未使用但无法再使用。所以这是一段失去的记忆。
对于 Variable_2,数据类型 INT 需要 16 位,因此它使用 2 个完整字节。与 Variable_4 相同,其数据类型为 WORD。
对于 Variable_3,我们占用了 4 个字节,因为它是 REAL 数据类型。这就是为什么 DB2 的偏移量分别为 0.0、2.0、4.0 和 8.0。
DB3 和 DB4 执行相同的概念。但由于变量的数据类型顺序不同,内存表示也会不同,因此偏移量也会不同。DB3 和 DB4 见图 9 和 10。看看根据前面的解释你是否能理解表示法。
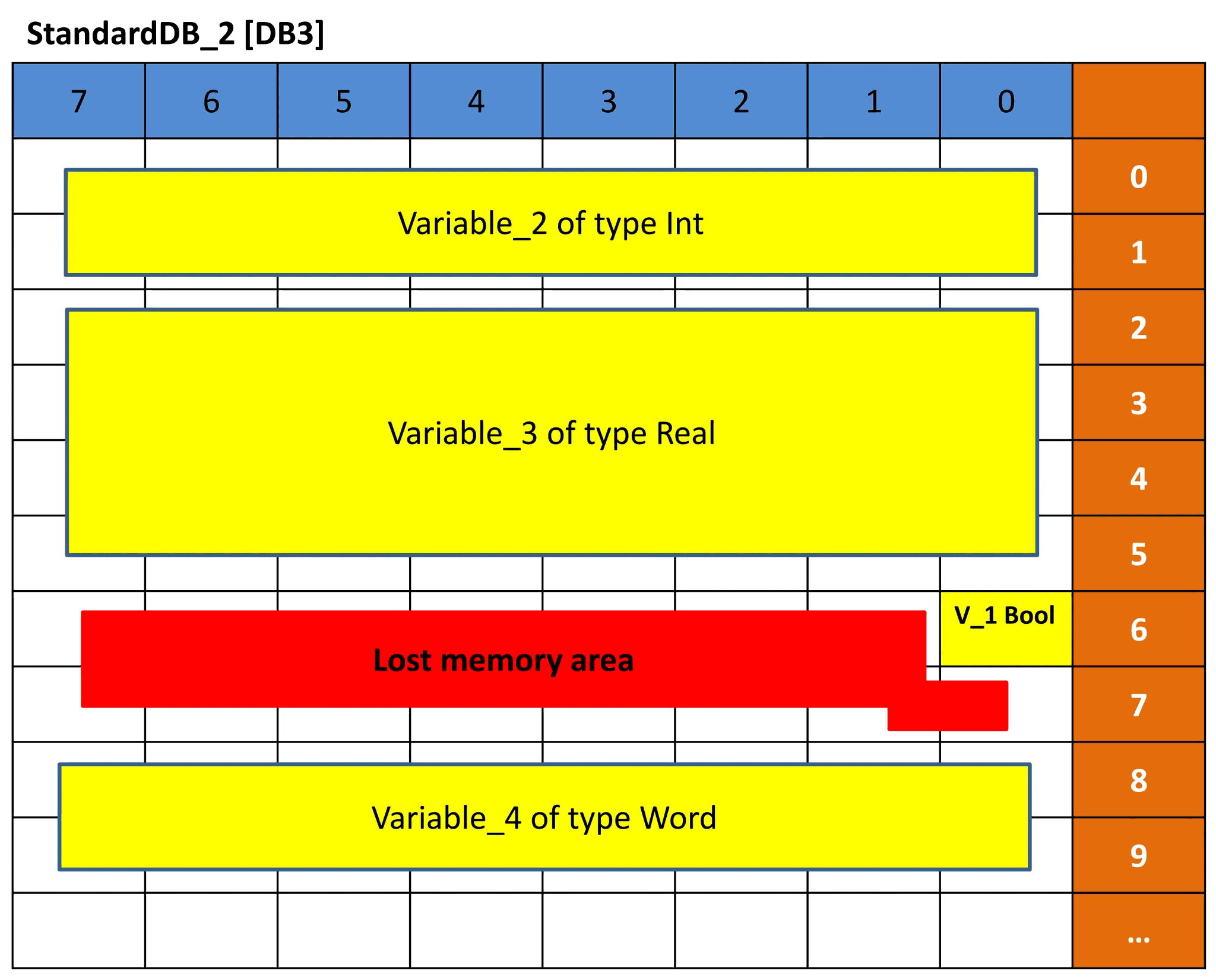
图 9 – DB3 的内存表示
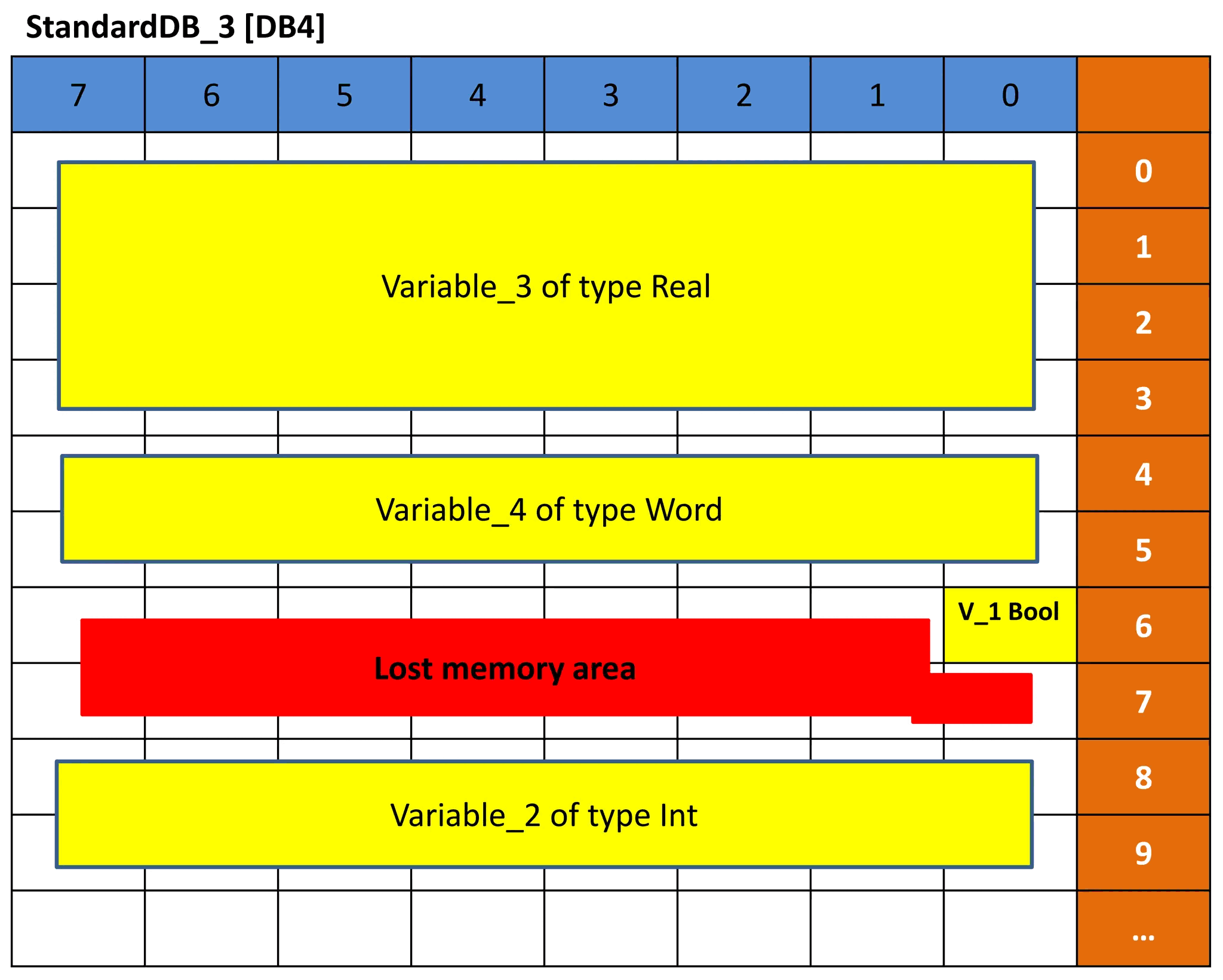
图 10 – DB4 的内存表示
因此,当您使用标准数据库时,声明变量时必须小心,因为每次定义新的 BOOL 变量时都会造成内存损失。
如果您在数据库列表的末尾声明新变量,则偏移量将扩展以包含您的新变量。但是,如果您在旧变量之间或在数据库的开头声明新变量,则会发生其他情况。见图11。

图 11 – 声明一个新变量
您会注意到的第一件事是您的偏移量现在丢失了,您必须编译代码才能重新建立新的偏移量。见图12。

图 12 – 通过重新编译代码重新建立偏移量
您是否注意到变量的寻址 (OFFSET) 现在发生了怎样的变化?
例如,REAL 标签的偏移量为 2.0,但在添加新的 TestVariable 后,同一 REAL 标签的寻址 (OFFSET) 现在为 4.0,见图 13。

图 13 – 添加 TestVariable 后的偏移变化
因此,当添加新变量时,所有旧变量的寻址都发生了变化。这意味着程序中需要写入或读取某个变量值的任何指令现在都将查看指令中分配的地址,但现在该地址具有与预期不同的数据。
简而言之,你的整个逻辑现在已经混乱了。这会带来很多麻烦。更不用说现在添加新变量后您会丢失额外的内存。见图 14。

图 14 – 添加 MOVE 指令
让我们添加一条 MOVE 指令,将值 1 移至 Variable_2 标签中。查看 MOVE 输出的地址如何为 %DB2.DBW2。
现在,让我们向 DB2 添加一个 INT 类型的新变量。见图15。

图 15 – 添加新的 INT 变量
当您添加新变量时,偏移量将丢失,并且 PLC 不再知道 MOVE 指令的 OUT1 的目的地在哪里。
我们需要编译程序来重新加载新的偏移量。见图16。

图 16 – OUT1 的新地址
您看到 OUT1 地址现在有何不同了吗?现在是 %DB2.DBW4 而不是 %DB2.DBW2。这是使用标准数据块的一个非常大的缺点。
什么是优化数据库?
优化数据块和标准数据块的区别在于,优化数据块内部的变量没有被分配到固定的地址,而是给变量赋予一个符号名称,而且数据块的结构也不像标准的那样固定。数据块,因此在声明新标签时不会丢失内存,也不会更改地址。 见图 17。

图 17 – 在优化块中声明新标签
因此,在优化数据块中声明新标签不会影响其余标签,因为它们是由符号名称而不是绝对寻址定义的。
优化的数据块将不允许您在使用其中定义的标签时使用地址。见图18。

图 18 – 使用优化块的绝对寻址
正如您在最后一张图片中看到的,优化数据块不允许绝对寻址,只允许符号名称。见图19。

图 19 – 使用带有优化 DB 的符号名称
优化访问的数据块的优点
具有优化访问的数据块没有固定定义的结构。数据元素(标签)仅分配一个符号名称,并且不使用块内的固定地址。
元素会自动保存在块的可用存储区域中,以便内存中不存在间隙。与标准 DB 相比,这可以实现内存容量的最佳利用,并避免内存丢失。
这具有以下优点:
- 您可以创建任何结构的数据块,而无需注意各个标签的物理排列。
- 由于数据存储是由系统优化和管理的,因此始终可以快速访问优化的数据。
- 例如,间接寻址或来自 HMI 的访问错误是不可能的。因为现在有地址,每个标签只有唯一的符号名称。
- 您可以将特定的单个标签定义为保持性。在标准 DB 中,您只能将整个块定义为保持性。
结论
与标准数据库相比,优化数据块有很多优点。在向块添加新变量时,使用符号名称有助于避免标签的任何地址更改。
通过优化块,不会丢失任何内存区域。与使用标准数据库时发生的情况相反。



